Home » How » Industries » Technology » Natural Language Translator
The Client was looking to improve performance of an already optimized algorithm by 100x and to identify what sections of the algorithm are suitable for further optimization.
Our team decomposed the algorithm and ran tests and measurements to identify the steps of the algorithm that are most time consuming.
After this analysis, the team started to investigate some quantization and dequantization techniques to improve the performance based on some public whitepapers.
Also, some new features for the targeted hardware were to be built for improved performance. All these techniques were new to the team and we had to have a quick ramp up time in order to stick to the project timeline.
The team analyzed both the high-level model topology (Python code) and the low-level architecture layers in order to optimize a neural net-based system for the inference step – the actual translation execution.
We used C++ and Assembly to optimize a network topology that translates text from one language to another. We optimized the code for the latest Intel CPU Sky-lake architecture Xeon.
For the algorithm optimization, we used quantization along a carefully optimized usage of the CPU caches, taking advantage of the AVX512 hardware support. This process required a deep understanding of the hardware architecture and of the network topology.
Moreover, we started working to implement support for the next generation of CPUs, in order to achieve an even higher speed/accuracy optimization.
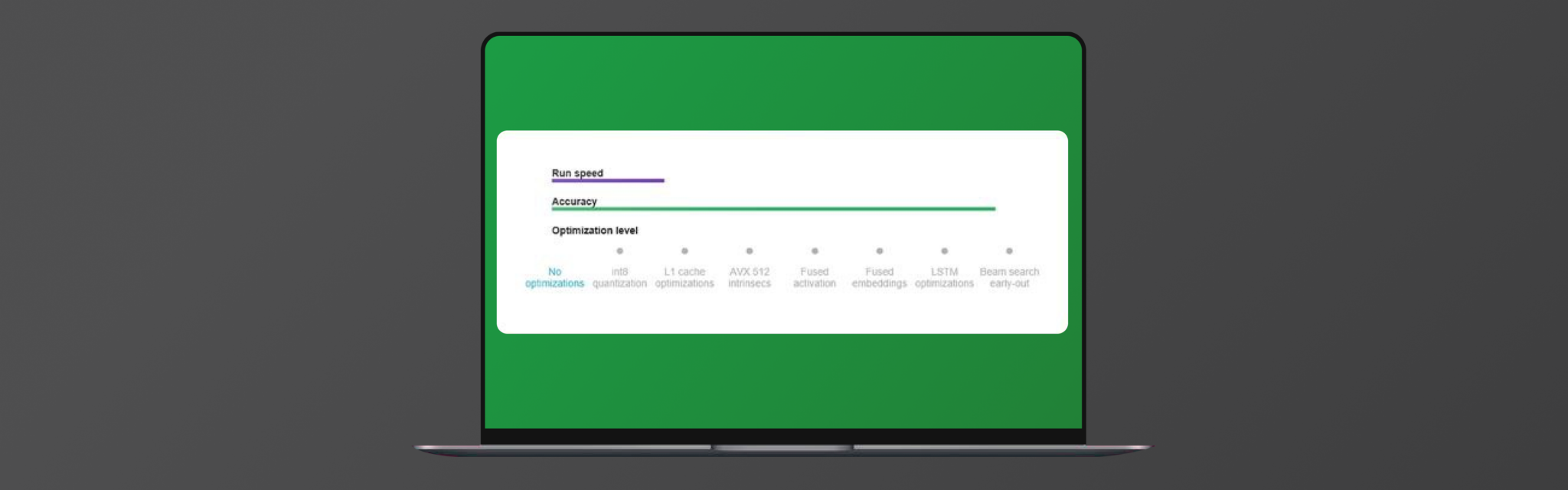
We created a flexible solution with multiple levels of optimization, each representing higher speed and lower accuracy. Users can select among multiple levels of optimization and set their speed vs. accuracy trade-off.
The project development was split in a few phases to make sure we keep the same functionality and accuracy. The following phases were rolled out during the project life cycle:
The latest computer science innovations are improving the quality of automatic translation services in terms of speed and accuracy: topologies like NMT (neural machine translation) can take advantage of newer and more efficient hardware based on CPU architectures like Intel Sky-Lake.
These technologies express their full potential when the software is fully optimized to match the hardware platform.
The client incorporated the new algorithm in a machine learning library delivered with the new hardware.








