
Insights
Everyone Wants AI, but Data Orchestration Comes First
Everyone Wants AI, but Data Orchestration Comes First Enterprise AI conversations often start in the wrong place. They focus on models, talent, or investment levels,
Your Definitive Guide
As industries from healthcare to fintech to IoT and beyond harness the transformative power of ML to revolutionize operations, customer engagement, and product development, the mastery of ML project delivery becomes crucial.
This article delves into the essence of successfully implementing ML projects, exploring strategic approaches, the comprehensive life cycle from conception to deployment, and real-world industry applications. With the global ML market on track to soar beyond $500 billion by 2030, we unveil the methodologies, best practices, and insights necessary for technology companies to navigate the intricate journey of ML project delivery—turning complex challenges into groundbreaking opportunities for growth and innovation.
Embarking on a machine learning project is a complex journey that requires meticulous planning, execution, and continuous refinement. This journey, aka Machine Learning Project Life Cycle, encompasses a series of critical steps designed to guide software development teams from the initial project conceptualization to its successful deployment and ongoing optimization.
Understanding this life cycle is essential for any organization aiming to leverage ML technologies to solve business problems, innovate, and gain a competitive edge.
Identifying the core business problem and defining the ML solution’s scope marks the beginning of any ML project. This phase is crucial as it sets the direction for the entire project, requiring a clear understanding of the business objectives and how ML can be used to achieve them. A well-defined problem statement ensures the project remains focused and measurable.
A deep dive into the problem definition and scope phase reveals its strategic significance. This stage is about identifying a problem and understanding the context in which the ML solution will operate. It requires collaboration between data scientists, domain experts, and business stakeholders to ensure the problem is well-defined and aligned with the organization’s goals. An in-depth exploration of this phase often involves conducting feasibility studies, assessing data availability, and setting realistic expectations for what ML can achieve. At this stage, implicit risks and assumptions should be identified and documented. This step helps develop a risk assessment strategy and define a minimum viable product (MVP).
Data is the most crucial aspect of ML projects. Data collection, cleaning, and preparation are foundational steps that significantly impact the project’s success. High-quality, relevant data is essential for training accurate models. This stage involves gathering sufficient data and ensuring it is representative and free from biases that could skew the model’s outcomes.
The data collection and preparation is arguably one of the most challenging and time-consuming stages in the ML project life cycle. Advanced techniques such as data augmentation, feature engineering, and dealing with imbalanced datasets are crucial for preparing data that can train robust ML models. This phase also involves ethical considerations, especially regarding privacy and bias, ensuring data handling practices comply with legal and social standards. An elaborate approach to data preparation enhances the model’s performance and fairness and transparency, which are essential for its acceptance and success.
Selecting the appropriate algorithms and training the models are pivotal steps where the theoretical meets the practical. The choice of algorithm depends on the nature of the problem, the type of data available, and the desired outcome. Training involves feeding data into the model and adjusting it until it reaches an acceptable level of accuracy.
Regarding model selection and training, the depth of exploration involves understanding the trade-offs between different algorithms and considering factors such as accuracy, interpretability, and computational efficiency. This phase often requires iterative experimentation with various models to identify the one that best addresses the problem. Advanced techniques, including hyperparameter tuning, cross-validation, and ensemble methods, are crucial in optimizing model performance. Furthermore, a comprehensive approach to training also addresses the challenges of overfitting and underfitting, ensuring that the model generalizes well to new, unseen data.
Deploying ML models into production environments and integrating them with existing systems pose significant challenges. It requires careful planning to ensure the model performs as expected in real-world scenarios and can scale according to demand. Strategies for successful integration often involve cross-disciplinary teams working collaboratively to address technical and operational hurdles.
The integration and deployment phase is where the ML model transitions from a theoretical construct to a practical, operational tool. A deeper examination of this stage involves addressing the technical challenges of deploying models in diverse environments, from cloud-based platforms to edge devices. It also requires a focus on creating scalable and maintainable systems supporting the model as it processes real-world data. This phase often involves collaboration with IT and operations teams to ensure the seamless integration of ML models with existing business processes and systems, addressing latency, scalability, and security issues.
Post-deployment, continuous monitoring is vital to ensure the model’s performance does not degrade over time. This includes setting up mechanisms for periodic retraining with new data, updating the models to adapt to changing conditions, and ensuring that the solution remains aligned with business objectives.
Monitoring and maintenance are critical for sustaining the performance and relevance of ML models over time. An in-depth approach to this phase includes implementing comprehensive logging and alerting systems to detect performance drift, model degradation, or data anomalies. Continuous monitoring enables timely adjustments and updates to the model, ensuring it adapts to changes in the data or environment. Additionally, this phase involves evaluating the impact of the model on business outcomes and user experiences, facilitating ongoing improvements that align with evolving business goals and market conditions.
A feedback loop allows for the continuous refinement of ML models based on their performance in real-world applications. This iterative process ensures that the models stay relevant and continue to provide value, making it an essential component of the ML project life cycle.
Establishing an effective feedback loop is vital for the iterative improvement of ML models. This process involves collecting and analyzing feedback on model performance and outcomes from various stakeholders, including end-users, business leaders, and data scientists. A deeper exploration of the feedback loop emphasizes the importance of leveraging this feedback to refine data collection practices, adjust model parameters, and even revisit the problem definition and scope. By closing the loop between model performance and subsequent iterations, organizations can ensure their ML solutions remain dynamic, relevant, and increasingly effective at meeting their objectives.
Delivering machine learning projects successfully is a complex effort that requires strategic planning, execution, and management. Effective strategies for delivering ML projects contain a broad spectrum of practices, from fostering a culture of collaboration and innovation to adopting agile methodologies and ensuring rigorous data management. In this section, we delve deeper into these strategies, highlighting their significance and offering insights into how they can be implemented to enhance the success rate of ML projects.
One of the key strategies for successfully delivering ML projects is fostering a culture of collaboration among multidisciplinary teams. ML projects typically involve stakeholders with varied expertise, including data scientists, software engineers, business analysts, and domain experts. Encouraging open communication and collaboration among these groups is essential for leveraging their diverse perspectives and skills. This collaborative environment facilitates the identification of innovative solutions to complex problems and ensures that ML solutions are aligned with business objectives and user needs.
Adopting agile project management methodologies is another effective strategy for ML projects. Agile practices, characterized by iterative development, flexibility, and continuous feedback, are particularly well-suited to ML projects’ experimental and evolving nature. By breaking the project into manageable sprints and incorporating regular reviews and adjustments, teams can respond to changes more quickly and efficiently. This approach allows for the early detection of issues and the opportunity to pivot strategies as necessary, significantly reducing the risk of project failures.
Given the critical role of data in ML projects, rigorous data management practices are essential. This involves implementing robust data collection, cleaning, processing, and storage processes. Ensuring the quality and integrity of data improves the accuracy and reliability of ML models and helps in complying with data privacy regulations and ethical guidelines. Advanced data management strategies include data governance frameworks, data lineage tools, and automated data quality checks, which collectively enhance the efficiency and effectiveness of ML projects.
Effective stakeholder engagement and communication are crucial for aligning ML projects with business goals and ensuring successful delivery. Regular updates, demonstrations, and feedback sessions with stakeholders, including project sponsors, end-users, and business leaders, ensure the project remains focused on delivering tangible business value. Transparent communication helps manage expectations, facilitate buy-in, and garner support throughout the project lifecycle.
The selection and application of software delivery methodologies play a crucial role in the success of machine learning projects. Given ML initiatives’ unique challenges and requirements, it’s imperative to choose methodologies that facilitate flexibility, collaboration, and continuous improvement.
Traditional software development methodologies like the Waterfall model follow a linear and sequential approach. This model is characterized by distinct phases such as requirements, design, implementation, testing, deployment, and maintenance, with each phase completed before the next begins. While this approach offers simplicity and predictability, it tends to be rigid, making it difficult to accommodate changes once the project is underway. In the context of ML projects, where experimentation and iterative refinement are key, the Waterfall model can limit flexibility and responsiveness.
Agile methodologies, on the other hand, prioritize flexibility, customer collaboration, and responsiveness to change. Agile approaches break the project into smaller, manageable increments or sprints, allowing teams to adapt and evolve their strategies based on ongoing feedback and discoveries. This iterative process is particularly beneficial for ML projects, which often involves exploring different models, algorithms, and data sets to optimize performance.
Flexibility and Adaptability: Agile methodologies allow ML teams to adapt to new findings, incorporate feedback, and pivot strategies as needed, which is essential given the experimental nature of ML projects.
Enhanced Collaboration: By encouraging regular communication among cross-functional teams and stakeholders, Agile methodologies foster a collaborative environment conducive to innovation and problem-solving in ML projects.
Incremental Delivery: Agile’s focus on delivering working software in small increments allows for early and frequent demonstrations of progress. This helps validate the direction of the ML project and builds stakeholder trust and engagement.
Risk Management: Agile methodologies facilitate early identification of issues, allowing teams to address challenges before they escalate. This is crucial for ML projects, where data or algorithmic challenges can significantly impact outcomes.
While Agile offers significant benefits for ML projects, adapting it to these initiatives’ specific needs can further enhance its effectiveness. Here are some adaptations for ML projects:
Integration of Data Science and Software Development Processes: ML projects require close collaboration between data scientists and software engineers. Tailoring Agile practices to facilitate this integration can help streamline the development, testing, and deployment of ML models.
Flexible Sprint Goals: Given the exploratory nature of ML work, defining sprint goals in terms of learning objectives or experimental outcomes rather than fixed deliverables can provide the necessary flexibility to accommodate the iterative experimentation and refinement of ML models.
Emphasis on Technical Excellence: Agile methodologies for ML projects should place a strong emphasis on technical excellence, including practices like continuous integration and continuous deployment (CI/CD), automated testing, and robust version control for both code and data. These practices are essential for managing the complexity and ensuring the quality of ML solutions.
Adaptive Planning for Uncertainty: ML projects often face data quality, model performance, and operational integration uncertainties. Incorporating adaptive planning practices, such as regular retrospectives and planning sessions to reassess and adjust project plans, can help teams navigate these uncertainties effectively.
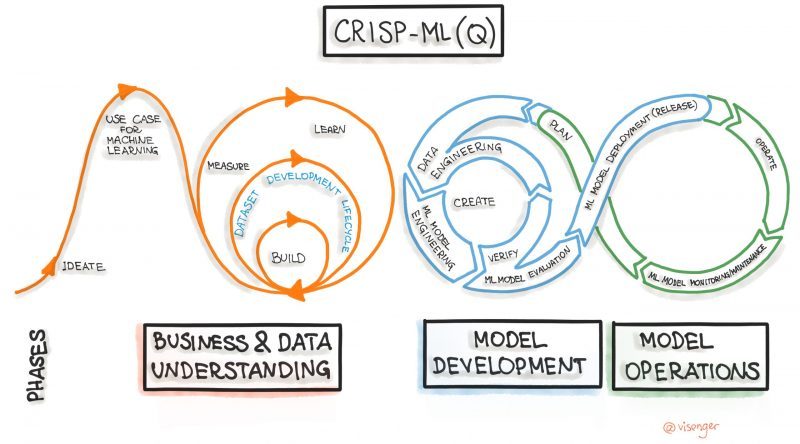
It’s recommended the ML development teams follow a Cross-Industry Standard Process for Data Mining (CRISP-DM) – the most widely-used analytics model and an open standard process model that describes common approaches used by data mining experts.
The components of the CRISP-DM methodology can serve as the main anchors and functional features of your project.
Let’s go through them briefly:
Business understanding: This phase focuses on understanding the overall project requirements, goals, and defining business metrics. This step also assesses the availability of resources, risks and contingencies, and conducts a cost-benefit analysis. In addition, core technologies and tools are chosen at this stage.
Data understanding: Data is a core part of any machine learning project. Without data to learn from, models cannot exist. Unfortunately, accessing and using data can take a very long time in many companies due to rules and procedures.
In this phase, the focus is on identifying, exploring, collecting, and analyzing data to achieve the project goal. This step includes identifying data sources, accessing data, creating data storage environments, and preliminary data analysis.
Data preparation: Even after the necessary data has been obtained, it is likely that it will need to be cleaned or transformed as it moves through the enterprise. In this step, the dataset is prepared for modeling; it includes subtasks of data selection, cleansing, formatting, integration, and data construction and builds data pipelines for ETL (extract, transform, load). The data will be changed several times. Understanding the processes involved in preparing these proposed subtasks is necessary for effective model building.
Modeling: After preparing the data, it is time to build and evaluate various models based on several different modeling techniques. This step consists of choosing modeling methods, developing features, creating a test project, building and evaluating models. The CRISP-DM manual suggests “repeat building and evaluating the model until you believe you have found the best one(s).”
Evaluation: The evaluation and analysis discussed above focus on evaluating the technical model. The Evaluation phase is broader as it assesses which model best fits the business objectives and the baseline. The subtasks in this phase evaluate the results (improving the model, performance metrics), analyze the processes, and determine the next steps.
Deployment: Your deployment strategy defines the complexity of this stage that includes deployment planning, monitoring and maintenance, final reporting, and validation.
Suggested sub-tasks include:
The application of machine learning across different industries has revolutionized how businesses operate, offering unprecedented opportunities for innovation, efficiency, and customer engagement. Each industry presents unique challenges and opportunities for ML, leveraging its capabilities to solve specific problems and achieve strategic objectives.
The automotive industry has been at the forefront of adopting ML technologies, significantly enhancing vehicle functionality and user experience.
Autonomous driving is the most ambitious application, where ML algorithms process data from sensors and cameras to make real-time decisions, mimicking human driving capabilities. This requires complex models that can accurately perceive environments and predict potential hazards. Predictive maintenance, another critical application, uses ML to analyze vehicle data, predicting failures before they occur, thereby reducing downtime and maintenance costs. Personalized in-car experiences have also become a focus, with ML enabling features like voice recognition and personalized content streaming, improving user satisfaction and loyalty. Integrating ML into automotive solutions demands high precision, reliability, and safety, with Agile and DevOps methodologies facilitating the rapid development and continuous refinement necessary to meet these strict requirements.
In retail, ML is transforming the shopping experience, supply chain management, and operational efficiency. Personalized shopping experiences, powered by ML algorithms, analyze customer data to provide tailored recommendations, improving engagement and sales. Inventory management and demand forecasting have seen significant improvements with ML, enabling retailers to optimize stock levels and reduce waste by accurately predicting consumer demand trends. These applications enhance customer satisfaction and contribute to sustainability by minimizing overproduction and waste. Agile methodologies and continuous integration and deployment practices allow retail companies to quickly adapt to changing consumer preferences and market dynamics.
The fintech industry leverages ML in several innovative ways to enhance security, customer service, and decision-making processes. Fraud detection and prevention benefit greatly from ML’s ability to analyze transaction patterns and detect anomalies, significantly reducing financial losses and increasing platform trust. Credit scoring and risk management applications have been transformed by ML, which can assess credit risk with greater accuracy by analyzing vast amounts of financial data, including non-traditional data sources. This has democratized access to credit, enabling lenders to serve a broader customer base more effectively. Algorithmic trading uses ML to analyze market data and execute trades at optimal times, increasing the efficiency and profitability of trading strategies. The fast-paced nature of fintech, combined with the critical importance of security and compliance, makes Agile and DevOps methodologies, including DevSecOps, essential for rapid, secure, and compliant ML solution development.
The IoT industry, characterized by its vast network of connected devices, has found ML a powerful tool for enhancing data analysis, decision-making, and automation. Predictive maintenance applications in industrial settings use ML to analyze sensor data, predicting equipment failures before they occur and significantly reducing downtime. Smart energy management systems leverage ML to optimize energy usage in buildings and cities, promoting sustainability and cost savings. Healthcare monitoring devices use ML to analyze real-time health data, enabling early detection of health issues and personalized care plans. The complexity of integrating ML models with diverse IoT devices and platforms needs Agile and DevOps practices to ensure scalable, flexible, and reliable deployment of these solutions.
ML in healthcare is revolutionizing patient care, diagnosis, and treatment processes. ML algorithms analyze medical images, genetic information, and patient data to assist in early diagnosis and personalized treatment plans, improving patient outcomes and reducing healthcare costs. Predictive analytics in healthcare can forecast outbreaks, patient admissions, and other critical events, enabling better resource allocation and preparedness. The regulatory environment of healthcare demands that ML solutions be effective and compliant with health data privacy and security regulations, making Agile methodologies tailored to accommodate these requirements essential for the successful delivery of ML projects in healthcare.
Delivering machine learning projects presents unique challenges that can significantly impact their success. These challenges arise from the fundamental complexities of ML technologies, the high expectations for business impact, and the integration of these projects into existing systems and workflows. Understanding these challenges is essential for developing effective strategies to address them.
The foundation of any ML project is data. However, obtaining high-quality, relevant, and sufficiently large datasets can take time and effort. The data may often need to be completed, accurate, or biased, leading to poor model performance. Addressing these issues requires robust data cleaning, augmentation, and validation processes.
With increasing concerns and regulations around data privacy (such as GDPR and CCPA), ensuring the privacy and security of data used in ML projects becomes a critical challenge. Projects must incorporate privacy-preserving techniques like differential privacy or federated learning and adhere to strict data governance policies.
With many algorithms available, selecting the most appropriate for a specific problem can be daunting. The choice impacts not only the accuracy but also the explainability and fairness of the model.
While potentially more accurate, complex models can be challenging to interpret and explain, especially to non-technical stakeholders. Balancing model complexity with the need for interpretability is a critical challenge in ML project delivery.
Integrating ML models with IT infrastructure and workflows can be complex and time-consuming. Challenges include ensuring the model can operate at scale, managing dependencies, and aligning with existing security protocols.
ML models can degrade in performance over time as data and environments change. Setting up processes for ongoing monitoring, maintenance, and updating of models is essential but challenging, requiring dedicated resources and expertise.
ML projects often require close collaboration between data scientists, software engineers, domain experts, and business stakeholders. Fostering effective communication and collaboration across these diverse teams can be challenging but is crucial for the project’s success.
There can be a significant gap between stakeholders’ expectations and what is technically feasible with ML. Managing these expectations, setting realistic goals, and communicating progress and challenges transparently are critical aspects of project management in ML.
Ensuring that ML models are fair and unbiased and do not perpetuate existing inequalities is a significant challenge. This requires careful consideration of the data used, the algorithms’ design, and the models’ potential impact on different groups.
ML projects must navigate a complex landscape of data privacy, security, and sector-specific requirements regulations. Ensuring compliance while achieving project goals requires a deep understanding of these regulations and, often, significant legal and compliance expertise.
An ML team can be different from a typical software development team setup. As organizations work to successfully create artificial intelligence, they need to consider and understand whom to involve in this process. The final skills to be sought-after include leadership, analytics, and design, data and data management, visualization, etc.
Modern machine learning teams are really diverse. However, in essence, they include specialists with strong analytical skills, the ability to understand data from various domains, train and deploy predictive models, and generate business or product insights.
Skills
Responsibilities
Tech stack
Skills
Responsibilities
Tech stack
Skills
Responsibilities
Tech stack
Skills
Responsibilities
Tech stack
Delivering ML projects is not just a technical venture but a strategic one that requires organizations to align their ML initiatives with a broader business context including goals and values. This alignment is crucial for ensuring that ML projects deliver tangible business results, enhance customer experiences, and drive innovation while adhering to ethical standards and regulatory requirements. Therefore, effective delivery of ML projects needs a holistic approach that encompasses the technical aspects of ML development and the project management, team dynamics, ethical considerations, and continuous learning and improvement mechanisms.
Navigating the ML project life cycle can be easier with a reliable tech partner who knows the industry’s unique peculiarities and the technology landscape. They offer a wide range of expertise, tried-and-true processes, and an extensive toolbox that may shorten project durations, reduce risks, and guarantee that ML projects are by your company’s objectives.
Furthermore, having a trustworthy partner helps you stay on the cutting edge and fully apply ML technologies to drive measurable business outcomes and positively impact societal advancements in a rapidly evolving field where new challenges and opportunities arise regularly.
Everyone Wants AI, but Data Orchestration Comes First Enterprise AI conversations often start in the wrong place. They focus on models, talent, or investment levels,

rinf.tech’s Databricks Partnership for Data & AI Platform Engineering in Regulated Enterprises Enabling Governed, Production-Ready Data & AI Operations rinf.tech customers gain access to production-ready Data and AI platforms,

The Hard Part of AI Starts After the Demo Works Enterprise investment in artificial intelligence continues to accelerate. Recent McKinsey surveys show that more than