
retail
Omnichannel Retail: Technologies, Challenges, and Opportunities
This article explores omnichannel retail. It covers its advantages, the technology driving it, the implementation challenges companies face, and future trends.
Machine learning allows computers to perform tasks intelligently by learning from data and examples rather than relying on pre-set rules. This is made possible by the large amounts of data being collected across industries and the rapid advancements in computer processing power, which improve the abilities of machine learning systems.
In this article, we’ll explore key reasons why quantization is important for AI projects and how it can benefit businesses.
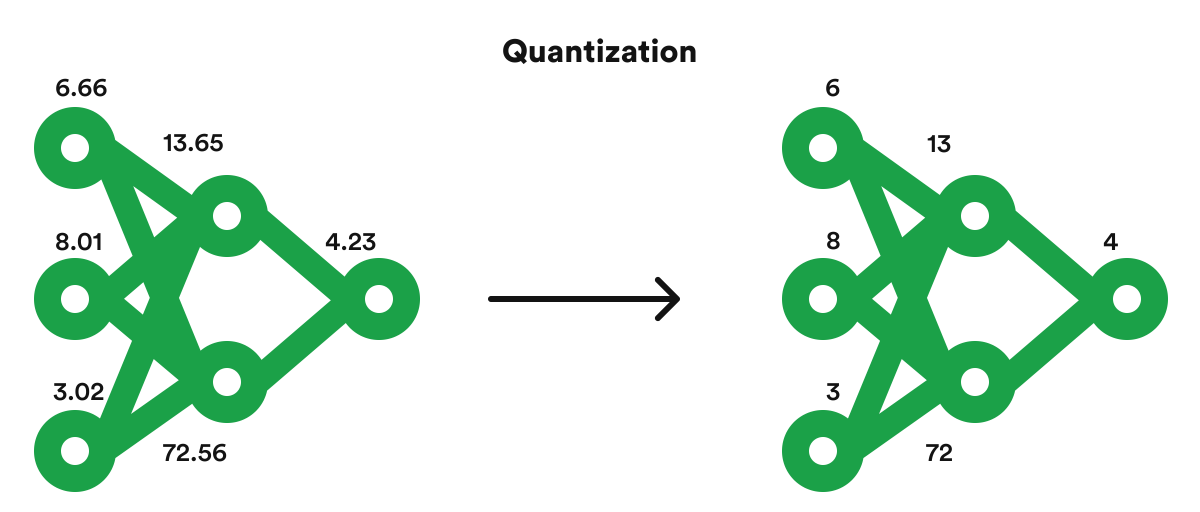
Artificial Intelligence is already being used in many commercial applications. As it continues to improve, the computational requirements for training and using AI are increasing. One of the most pressing concerns in this area is making AI more efficient while making predictions, known as inference. Quantization is a method of reducing computational demands and increasing the power efficiency of AI. It is an overarching term encompassing various techniques for converting input values to smaller output values.
Quantization improves performance and power efficiency by reducing memory access costs and increasing computing efficiency. Lower-bit quantization requires less data movement, which reduces memory bandwidth and energy consumption. Additionally, mathematical operations with lower precision consume less energy and improve computation efficiency, thereby reducing power consumption.
Furthermore, using fewer bits to represent the neural network’s parameters leads to less memory storage.
The top 5 advantages of machine learning quantization in AI projects are as follows:
Quantization can dramatically reduce the memory and computation required to run the model by decreasing the precision of the model’s parameters and activations. As a result, running the model on hardware with constrained resources, such as embedded systems or mobile phones, may be more effective.
Quantization can also enhance a model’s performance by minimizing noise in the parameters and activations. Since the model is less likely to be impacted by tiny differences in the input data, this can result in more accurate and stable predictions. It can help strengthen the model’s resistance to hostile cases.
Quantization can partially boost security by decreasing the model’s parameters’ precision. An attacker may find it more challenging to obtain accurate parameter values, making it more difficult to understand how the model behaves through reverse engineering.
Given that power consumption is a significant concern, quantization is a crucial technique for implementing deep learning models on low-power devices like smartphones, IoT devices, and embedded systems. Quantization can also speed up inference because low-precision processes typically occur more quickly than high-precision ones.
A model becomes more versatile for deployment in many situations thanks to quantization, which also lowers a model’s memory and processing requirements. Quantized models can operate effectively on various hardware architectures, including CPUs, GPUs, and specialized hardware accelerators like Tensor Processing Units (TPUs) and Application-Specific Integrated Circuits, by decreasing the precision of the weights and activations (ASICs). This is so that inferences can be made more quickly and power-effectively. Low-precision operations can be effectively implemented on a variety of hardware platforms.

Deep learning models can be quantized through post-training and quantization-aware training.
After training, a pre-trained model is converted to a lower-precision integer representation as part of post-training quantization. The method entails evaluating a model’s weights and activations on a test dataset to determine their ranges of values.
Post-training quantization offers several advantages, including less memory utilization and accelerated inference.
On the other hand, quantization-aware training involves integrating fictitious quantization operations during training to simulate the impact of quantization on the model’s computations, as opposed to post-training quantization, which reduces the precision of a pre-trained model after training. As a result, the model can acquire more appropriate representations for quantization.
Quantization-aware training offers several advantages, including enhanced accuracy compared to post-training quantization.
There are best practices that improve accuracy and efficiency when applying quantization approaches to deep learning models, including:
The accuracy of a model’s weights and activations should match the specifications of the task and the available hardware. Precision selection should take task sensitivity and hardware memory into account.
Using a representative dataset for training and validation can enhance the quality of quantized models. This dataset should be sufficiently large to account for task complexity and accurately reflect the data distribution the model will encounter.
To guarantee that the appropriate level of precision is obtained, it is crucial to check the correctness of quantized models. To achieve this, it is possible to assess the model’s performance on a validation or test set and compare it to the model’s accuracy. Quantifying deep learning models requires monitoring accuracy to maintain the appropriate level of precision while increasing the model’s effectiveness.
Several successful AI projects have used machine learning quantization to improve performance and reduce the computational resources required.
Some examples include:
Google’s TensorFlow Lite is a lightweight version of TensorFlow, the popular open-source machine learning framework. TensorFlow Lite is designed to run machine learning models on mobile devices, embedded systems, and other resource-constrained devices. One of the critical features of TensorFlow Lite is quantization, which converts high-precision floating-point representations of model parameters and activations to lower-precision integer representations. This results in a smaller model size, as fewer bits are required to represent the same information.
NVIDIA’s TensorRT is a deep learning inference optimizer and runtime library designed to run on NVIDIA GPUs. It is designed to optimize deep learning models for deployment in production environments, and one of the key ways it does this is through quantization. Quantization in TensorRT involves converting the high-precision floating-point representation of model parameters and activations to lower-precision integer representations. This reduces the memory footprint of the model and allows for faster computation, as integer operations are typically quicker than floating-point operations on GPUs.
A leading semiconductor manufacturer benefited from rinf.tech’s expertise in deep learning to achieve hardware-specific optimization for Natural Language Translator algorithm. They were looking to improve the performance of an already optimized algorithm by 100x and to identify what sections of the algorithm are suitable for further optimization.
Our solution utilized quantization in combination with a meticulously optimized use of CPU caches, taking advantage of the AVX512 hardware support. The project success was due to our thorough understanding of the hardware architecture and network structure. Furthermore, we are working towards incorporating support for the next generation of CPUs to achieve an even higher optimization of speed and accuracy.
We have developed a versatile solution that provides multiple optimization levels, with each group offering a different trade-off between speed and accuracy. Users can choose from optimization levels to find the best balance between performance and accuracy.
Machine learning quantization is an effective method for enhancing the effectiveness and performance of AI projects. It is a crucial tool for implementing machine learning models in real-world settings where productivity and performance are essential. It is now simple to integrate quantization in AI projects thanks to tools like Google’s TensorFlow Lite and NVIDIA’s TensorRT, which offer libraries and tools for quantizing models and improving their performance.
Overall, machine learning quantization offers advantages that make it necessary to be considered when deploying machine learning models in practical applications. Quantization enables new use cases, increases AI solution speed and efficiency, and maximizes the capabilities of machine learning technology.
This article explores omnichannel retail. It covers its advantages, the technology driving it, the implementation challenges companies face, and future trends.

A comprehensive overview of how fintech innovations drive significant changes in the retail industry.

In this article, we explore a current retail technology landscape and trends shaping the industry, retail tech use cases, as well as what the future holds for retail tech.